

DynamoDB Importer
This blog will demonstrate the high throughput rate that DynamoDB can handle by writing 1 million records in 60 seconds with a single Lambda , that is approximately 17k writes per second. This is all done with less than 250 lines of code and less than 70 lines of CloudFormation.
We will also show how to reach 40k writes per second (2.4 million per minute) by running a few of the importer Lambdas concurrently to observe the DynamoDB burst capacity in action.
UPDATE: There are alternatives to this manual method, AWS released Import and Export capabilities for DynamoDB in Aug 2022.
Knowing the Limits
It is always nice to talk about the limits and capabilities of DynamoDB but few people get to actually test them and walk the walk. This blog originated from this dev.to discussion in the comments. It will also hopefully be one in many DynamoDB blogs to come.
DynamoDB is an Online Transactional Processing (OLTP) database that is built for massive scale. It takes a different type of mindset to develop for NoSQL and particularly DynamoDB, working with and around limitations but when you hit that sweet spot, the sky is the limit. This post will test some of those limits.
The fastest write throughput that I heard of was in this AWS blog post were they was pushed to 1.1 Million records per second! We won’t be going that high, as we would need to contact AWS to get a quota increase, for now we just want to demonstrate the ability and show some code. Enough chit chat, let’s get to the good stuff.
Pseudo code
This app consists of a NodeJS Lambda function that streams a S3 file and then imports it into DynamoDB using the Batch API.
What’s happening behind the scenes:
- Streaming the file from S3 allows us to read the file in chunks and not fill the memory. It still counts as a single S3 read operation with the added benefit of not storing the full file in memory.
- The data can be generated by running a script in /data-generator/generate.js. It will output a CSV file of 3 million lines of person records with a size of about 250MB.
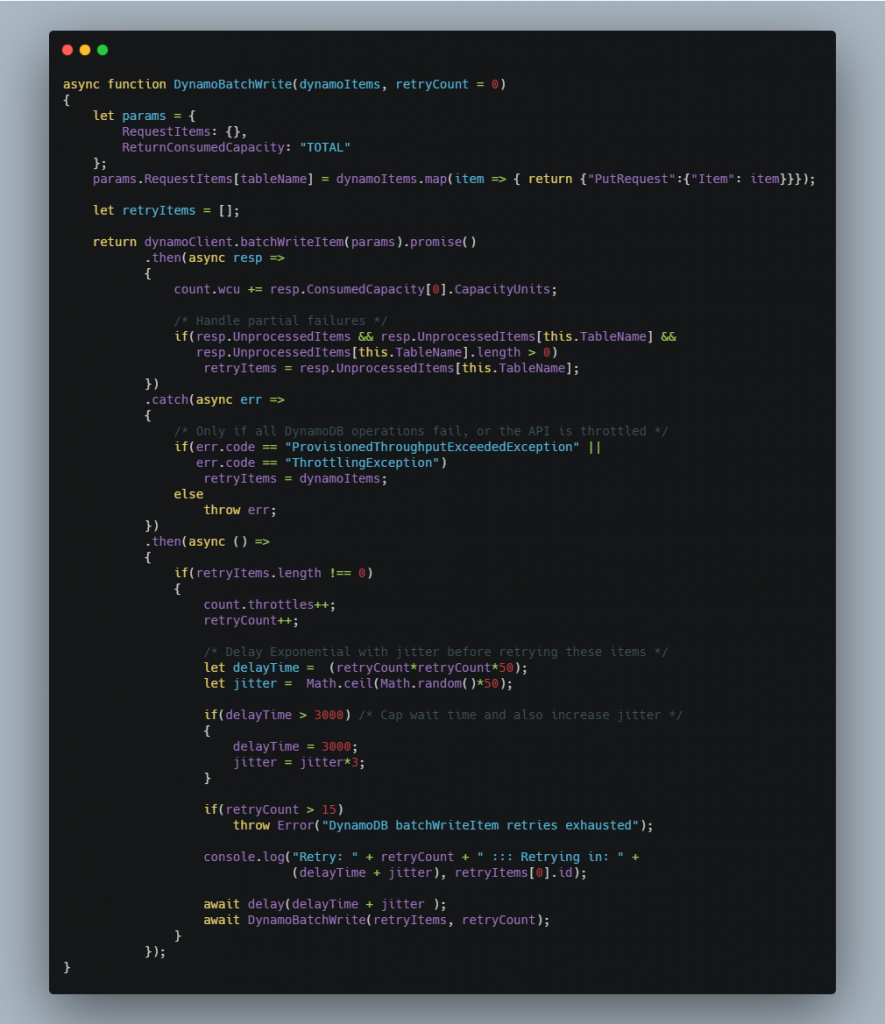
- Rows are read until 25 records are accumulated ; these are then used to create a DynamoDB batch write promise. X amount of DynamoDB batch write promises are stored in an array and will be executed in parallel but limited to only Y concurrent executions.
- DynamoDB API Retries are set to 0 on the SDK client. This is so that we can handle partial batch throttles. This is done by adding the unprocessed items returned from the batch write call into an array and then calling the same batch write function recursively. This retry mechanism is hard coded to stop at 15 calls and to have exponential back off with a 50ms jitter between retires.
- HTTP Keep Alive on the AWS SDK is turned on with the environment variable: AWS_NODEJS_CONNECTION_REUSE_ENABLED = 1. DynamoDB API operations are usually short lived and the latency to open the TCP connection is greater than the actual API call. Check out Yan Cui’s post here.
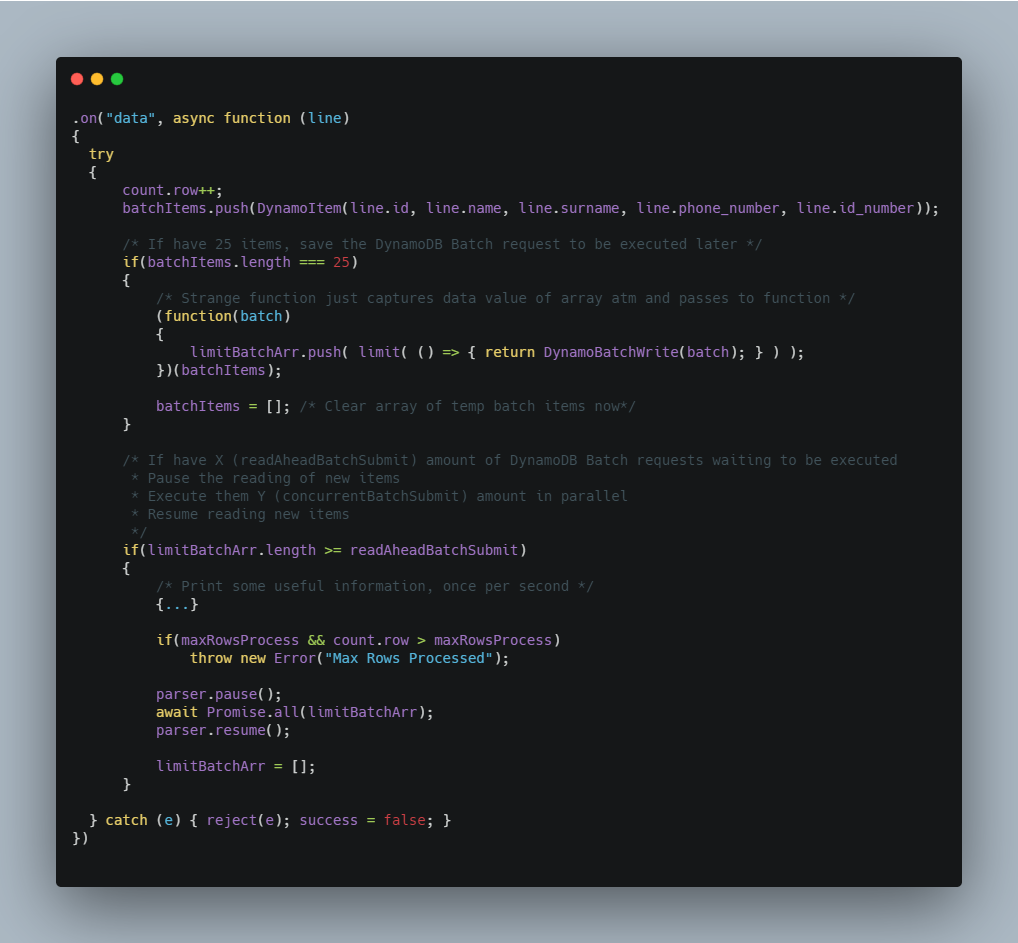
For example; if X (batch write promises) = 40 and Y (the parallel execution limit) = 20 it means that the stream will be read until it has 25*40 = 1000 records and then execute 20 batch writes operations at a time until all 40 is complete. Then it will repeat by reading another 40 batches and so on. The S3 stream pausing gives the DynamoDB rate limiting a bit of time to recover, compared to reading ALL the data at once and then just hammering the Dynamo API nonstop. The pausing gives it a bit of a breather.
The rest is just boiler plate to log the throughput, providing arguments through environment variables, comments and handling permissions. The actual code will be far less if this is removed.
Code walk through
The full source code can be found here -> https://github.com/rehanvdm/DynamoDBImporter. I am only going to highlight the few pieces that are of importance.
To prevent a HOT partition while writing to Dynamo, a UUID v4 is used as the Partition Key(PK) with no Sort Key (SK).
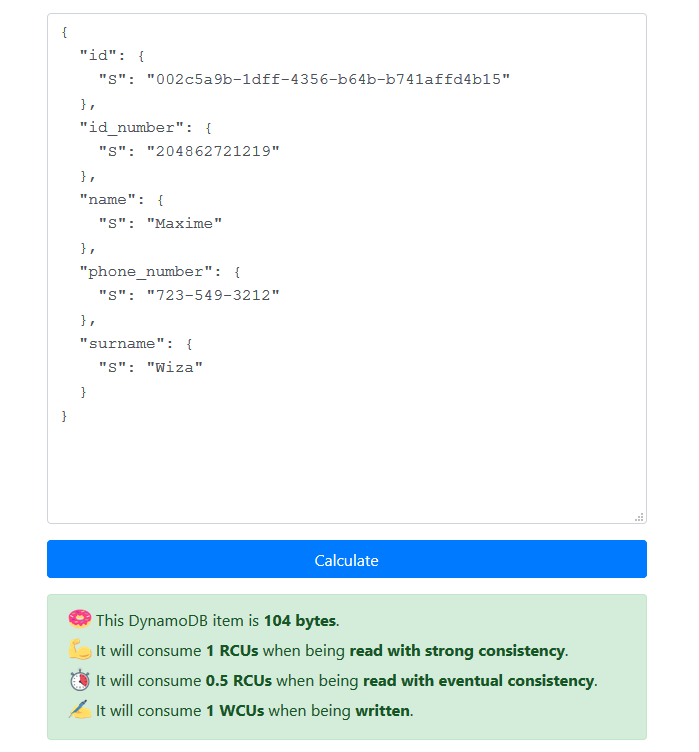
A single data record/row is kept small and fits within 1KB so that 1 record equals 1 WCU. This makes the tests and calculations easier. This is a nice tool that gives you the size of a single record as seen below.
Below the batch writing function as explained in Pseudo code with manual retries to handle partial batch failures.
Then the streaming function that reads from S3 and builds the array of batches.
The proof is in the pudding
A single lambda running at full power (Memory = 3GB) can write 1 Million records into a DynamoDB table (first smaller spike on graph). Running a few concurrent lambdas, we can test the burst capacity of the table (right side larger spike).
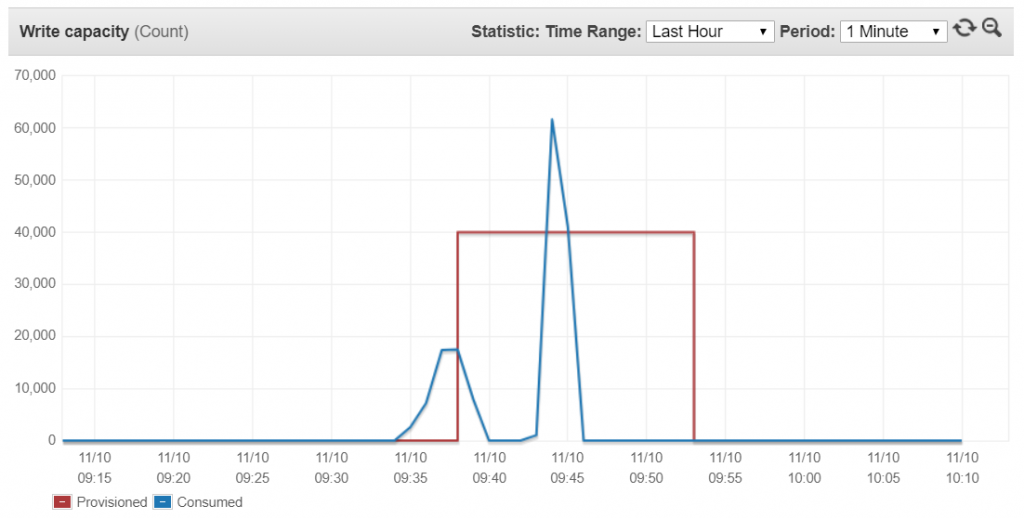
The CloudWatch metrics below shows total capacity consumed for the duration of the test per minute.
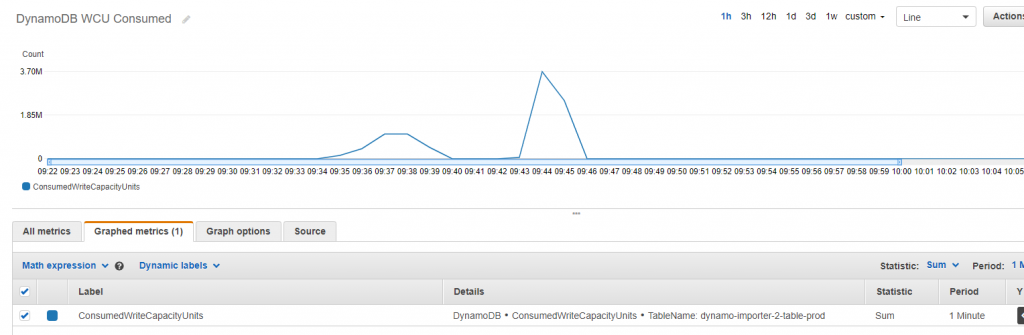
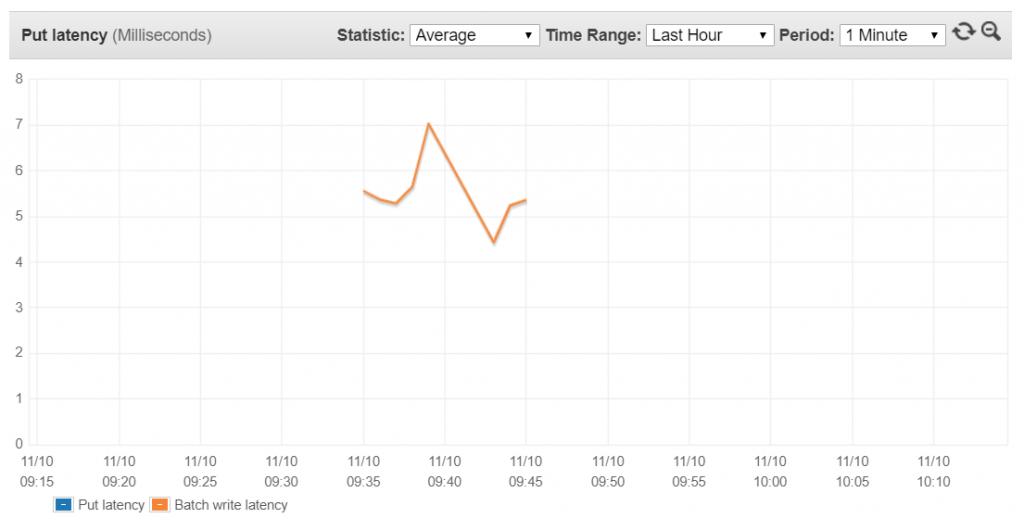
What is amazing is that the Batch Write API Latency stayed below 10ms for all of the writes, there were some throttles though but the program handled and retried them correctly.
Things to keep in mind
A few things that I did/noticed while coding and doing the experiment.
- The first time the tables WCU’s were scaled to 40k, it took about 1 hour to provision, I hope I didn’t get charged for that hour. After that switching between a lower capacity and back to 40k took about 1 minute.
- The AWS SDK TCP keep alive makes a huge difference.
- Provisioned capacity billing mode can go from zero to full, almost instantaneously. On demand takes a while to warm up, Yan Cui wrote a great post on this behavior here. There is a “cheat” to get a warm (40k) table right from the get-go with on demand pricing. You can set your table to provisioned 40k WCU and then after it has been provisioned, change back to on demand billing.



